
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Realtime
- Transformer #classification #SOTA #Google
- CVPR
- objectdetector
- Manmohan #UnconstrainedComputerVision
- POSE ESTIMATION
- XiaomingLiu #PersonIdentification
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- vit
- DeepDoubleDescent #OpenAI #어려워
- ICCV19 #Real-World #FaceRecognition
- coco
- hourglass
- cornernet #simple #다음은centernet #hourglass생명력이란
- IvanLaptev
- np-hard
- centernet
- Today
- Total
HyperML
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT) 본문
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)
곰돌이만세 2021. 7. 18. 10:56Transformer 는 본래 attention mechanisim 에 기반하여 language model의 학습을 위해 설계되었다.
간단한 구조와 적은 inductive bias 및 큰 weight capacity로 거대하게 모델을 만들고 거대한 데이터 학습에도 그 성능이 포화되지 않고,
언어모델의 self-supervised 학습 -> finetune 과정을 쉽게 수행함으로써 BERT, GPT와 같은 거대모델의 출현 및 다양한 task 활용을 이끌어 자연어 처리분야의 사실상 표준(de-facto standard)이 되었다.
이러한 transformer가 vision task에 적용될 것이라는 것은 누구나 예상할 수 있었고 많은 시도가 있었지만,
ViT에 이르러서야 구글의 많은 데이터로 vision classification에서 그 SOTA 수준의 성능을 입증할 수 있게 되었다.
이 리뷰를 통해 그 과정을 어떻게 풀어가는지 보고자 한다.
다만 논문의 형식 (특히 실험)은 이전에 구글에서 발표했던 BiT: Big Transfer를 따라가고 있다. 저자도 일부 겹친다. 이들은 기존 resnet의 모델을 크게 만들어 많은 데이터를 집어넣고 돌려서 나온 결과를 분석하였다. 어떤면에서 ViT는 BiT에 그저 transformer를 끼얹은 것 같은 느낌이 든다.
Introduction
널리 알려진 대로 Transformer에서 self-attention 기반의 아키텍쳐는 언어모델에서 흔히 사용되었다. 그러나 vision task에서는 여전히 CNN기반의 아키텍쳐가 주류였다. 이것을 비전에 적용하기 위해서 이미지를 patch로 쪼갰다. (서로 겹치지 않게)
기존 vision task에서 pretrain 으로 많이 사용하던 ImageNet은 transformer 기준으로 본다면 중규모 데이터셋에 불과하다. 실험에서는 ImageNet(100만)을 포함하여 구글 내부용 데이터셋인 JFT-300M(1400만 랜덤샘플링, 3억)을 이용하여 결과를 냈다.
그 결과 best model은 ImageNet 평가에서 88.55% acc.를 달성할 수 있었다. 이밖에 ImageNet-ReaL 90.72%, CIFAR-100에서 94.55%, VTAB에서 77.63%를 기록했다
Method
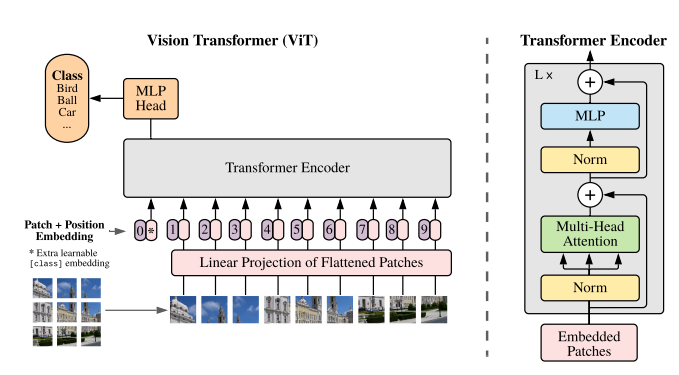
구조는 예상가능한대로 매우 심플한 편이다. 저자들은 standard한 transformer를 최대한 따랐다고 하며 아래의 과정을 거쳐 이미지를 처리했다.
1. 이미지를 정해진 patch수 (N) 로 쪼개고 (patch resolution : P, channels : C)
2. 각각을 embedding 한다
3. embedding 한 데이터를 linear projection 한 것을 position embedding 값을 각 embedding에 더하고 class embedding을 concat 한다 (기존 transformer와 동일)
4. transformer encoder에서 이 embedding을 처리해서 MLP로 feature vector를 계산하여 분류 task를 수행한다
이것을 식으로 나타내면 아래와 동일한데 큰 의미가 있는지는 모르겠다.

Transformer 짚고 넘어가기
Transformer 에 익숙하지 않은 분들을 위해 RNN을 안다고 가정하고 약간 설명하자면
(참조 : https://wikidocs.net/31379)

RNN에서 단어 토큰을 받아들여서 many-to-many 방식으로 번역 프로세스를 수행한다고 생각해보자
그러면 위 그림과 같이 그 과정을 단순화 할 수 있다
다만 ViT의 경우에는 위에서 feature 만 뽑아내면 되므로 encoder만 사용한다

아래 부터 위로 올라가면서 처리가되는 구조인데 아랫부분 embedding에는 아래 예시와 같은 단어들이 들어온다

transformer 가 기존 모델들과 다른 특이한 점은 바로 이런 점인데, 정해진 학습 weight가 있다기 보다는 입력된 문장의 단어간의 유사도를 기반으로 weight를 학습한다는 것이다. (위치와 의미 모두)
transformer에서는 동일한 문장을 embedding된 단어 하나씩 서로 비교해가면서 유사도를 측정하는데
위 예를 보면 우측의 it은 좌측의 모든 단어들과 match해서 유사도를 계산한다. 그래서 가장 연관성이 높은 단어에 대해서 높은 유사도를 가지게끔 학습을 한다.
그래서 각 단어 embedding 별로 key/query/value weight matrix가 존재하게 되며 transformer의 학습 대상은 이 matrix가 된다.
이 예에서는 query는 it이 되고 key는 동일 문장내 단어들이 된다 (어차피 key, query는 서로 같은 단어들을 가리키고 서로 역할만 바꿔서 동작) 나중에 동일 문장내 단어들에 대해 softmax 계산을 한 후 value를 곱해서 1문장에 대한 최종 결과(attention value)를 얻는다
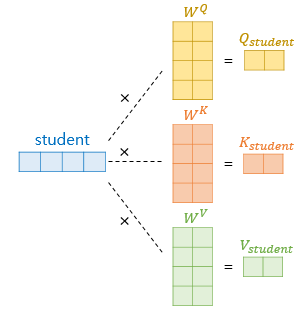

위 과정을 간단히 그림으로 나타내면 바로 위 그림과 같다.
식으로 나타내면 아래와 같다.

설명이 길었는데 어쨌든 transformer 결과 출력도 하나의 feature가 되는 셈이다
위 그림에는 multihead란 표현이 있는데 입력 embedding 단어 크기가 512라고 하고 head가 8개라고 한다면 64 size로 쪼개서 위 과정을 동일하게 계산하고 결과를 concat한 후 다시 차원을 원래 output에 맞게 맞추는 과정을 수행한다
이렇게 쪼개서 처리하면 embedding을 여러 측면에서 볼 수 있기 때문에 성능이 좋아진다고 한다. 대신 weight 크기가 head 개수에 비례하여 커지게 된다.
---------------------------------------------------------------------------------------------------------------------------
ViT에는 P x P 크기의 patch 하나하나가 바로 단어가 되는 셈이다. 다만 그냥 생각해 봤을 때 단어 사전이 존재하는 자연어 분야 대비 그런 것이 없는 image patch는 경우의 수가 많을 것으로 생각해볼 수 있다.
Inductive Bias
참조 : Inductive Bias 란?
[머신러닝/딥러닝] Inductive Bias란?
Inductive Bias란 무엇일까요? 최근 논문들을 보면 그냥 Bias도 아니고 inductive Bias라는 말이 자주 나오는 것을 확인할 수 있는데요! 오늘은 해당 개념에 대해 정리해보는 시간을 가지려고 합니다.
velog.io
"Wikipedia에서 정의를 빌려오자면, Inductive bias란, 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정 (additional assumptions)을 의미합니다."
"이러한 딱딱한 개념이 아닌 조금 더 비유적인 표현을 가지고 예시를 들어보겠습니다. 우리가 흔히 말하는 머신러닝/딥러닝을 input과 output의 데이터가 주어지면, 주어진 데이터에 맞는 함수를 가방에서 찾는 것이라고 비유해 보겠습니다. Inductive Bias는 우리가 함수를 찾는 가방의 크기에 반비례(가정의 강도와는 비례)되는 개념으로 보시면 될 것 같습니다. 실제로 거의 모든 함수를 표현할 수 있는 MLP(Multi-Linear Perceptron)의 경우 엄청 큰 가방이라고 생각하면되고, CNN(Convolutional Neural-Net)의 경우 전자보다는 작은 가방이라고 생각하면 될 것 같습니다."
정의에 따르면 CNN은 MLP보다 더 많은 가정이 들어가므로 (2차원, local 처리) 더 큰 inductive bias가 있다고 볼 수 있다. MLP와 transformer는 이 측면에서 서로 비교하기가 쉽지 않고 논문에도 비교에 대한 언급이 없다. 다만 transformer에 적용된 inductive bias는 바로 patch를 쪼개서 입력하는 것 정도로 이야기 하고 있다.
(위 표기중에 MLP는 multilayer perceptron이 옳은 표현이다.)
Experiments
아키텍쳐 자체가 심플하고 널리 알려진 구조를 가져다가 약간의 처리 + 거대한 데이터로 실험한 것이다보니 원리에 대한 내용보다는 실험이 많은 부분을 차지하고 있다.

datasets
- ImageNet (1k classes, 1.3M images)
- ImageNet-ReaL (위와 동일, cleand-up ReaL labels)
- ImageNet-21k (21k classes, 14M images)
- JFT (18k classes, 303M images)
- CIFAR10/100, Oxford-IIIT Pets
- Oxford Flowers-102
models
- BiT (ResNet, baseline, BN을 GN으로 변경한 버전)
- Noisy Student (EfficientNet B7을 기반으로 teacher-student 방식으로 weight를 늘려가며 self-train)
실험들
아무래도 기존의 task를 완전 새로운 메커니즘을 적용하다보니 실험거리가 많은 편이고 appendix에 실려있는 것 들중에도 의미있는 것들이 있어 함께 분석해 보았다.
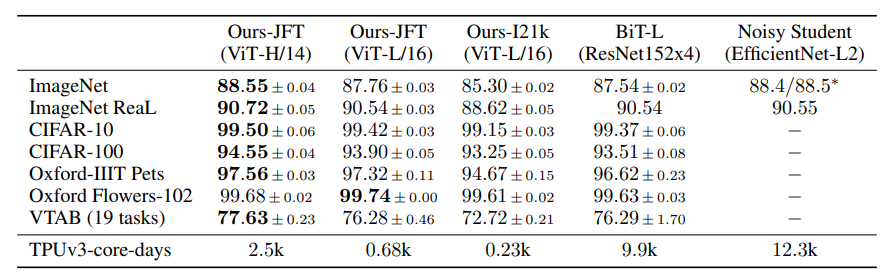
ViT-H/14가 거의 모든 dataset에서 SOTA를 기록했다. 특히 pretrain 에 들어간 비용 효율성 면에서 ViT가 기존의 BiT-L이나 Noisy Student와 현격히 차이나게 우수함을 알 수 있다.

(좌) ImageNet 평가 accuracy (우) Imagenet Few-shot 평가 (가로축 pretraining 샘플수)
위 실험에서는 데이터셋 크기를 늘려가면서 acc 측면에서 포화되는지 여부를 확인한 실험이다
두 실험 모두 CNN기반인 BiT 대비하여 학습데이터를 많이 투입해도 포화가 안되거나 덜 되는 것을 보여준다 같은 ViT 안에서도 B(base) 보다 L(Large)가 더 성능이 우수함을 확인할 수 있고 patch 개수가 적을 수록 더 우수한 것을 알 수 있다. 저자들은 우측의 차트를 보고 transfer learning을 이용해서 few-shot 으로 진행하는것이 앞으로의 방향성이라고 생각한다고 한다. (JFT 이미지를 본적은 없지만 ImageNet이랑 크게 다르지 않을 걸로 생각하는데 기뻐할 일인지는 잘 ...)
재미있는 것은 데이터가 적을 때는 CNN모델이 더 우수한 성능을 보인다는 점이고, 이는 저자들이 앞단의 embedding 부분을 cnn으로 처리한 hybrid 모델에서도 마찬가지 결과를 보인다. (다음 그림)

패치 size(16/32/14, 가로세로 해상도)가 클수록 총 패치개수가 줄어들고 연산이 줄어들며 정확도가 낮아진다.
Scaling Study


- 실험에 사용된 networks
R50x1, R50x2, R101x1, R152x1, R152x2 (pretrained 7 epochs)
R152x2, R200x3 (pretrained 14 epochs)
ViT-B/32, B/16, L/32, L/16 (pretrained 7 epochs)
L/16, H/14 (pretrained 14 epochs)
hybrids (끝의 32, 16등은 패치해상도가 아니며, downsampling을 얼마나 했냐의 의미임)
전반저긍로 ResNet(BiT)의 성능이 낮은 것을 알 수 있다. 같은 연산일 때 ViT가 BiT를 앞선다. 여기서의 포인트는 ViT와 Hybrid ViT의 비교인데 Hybrid 가 비슷한 정확도에서 더 적은 연산을 요구하는 것으로 보인다. 저자들은 CNN은 필요 없다는 듯한 태도를 보이면서도 hybrid 방식에 대한 실험결과를 남겼다. x축이 커질수록 gap이 줄어든다.
Self-Supervision
NLP task에 transformer가 인상적인 활약을 보이는 것은 그 자체의 scalability 가 훌륭한 것 뿐 아니라 large scale self-supervised pre-training이 가능하다는 저자들의 말에 공감한다. 저자들은 BERT에서한 것과 유사하게 masked patch prediction을 수행했고 ViT-B/16에서 79.9% (ImageNet) 를 달성했으나 supervised 방식에 비해 4% 뒤쳐지는 결과를 달성했다.
저자들은 masked patch prediction으로 50% 의 embedded patch를 corrupt 시키고, [mask] embedding을 80%, randon하게 다른 patch embedding 으로 대치(10%), 그냥 그대로 두기 (10)%로 처리하였다. JFT로 14 epoch을 돌려서 학습했다.
그래서 다음과 같이 진행을 했는데
1) 3bit color의 mean을 예측
2) 4x4 downsized patch 3bit color 예측(16x16의 미니버전)
3) L2를 사용해서 full patch 예측
놀랍게도 모두 잘 동작했고 3)번만 약간 부족한 결과를 보였다고 한다. 다만 숫자로 된 결과는 확인시켜주지 않았다.
Conclusion
저자들은 이전의 transformer를 이용한 이미지 인식 방법들과 달리 별도의 이미지를 위한 inductive bias를 도입하지 않았다고 강조한다. 그리고 그냥 패치를 가지고 NLP task와 동일하게 처리했는데도 놀라운 성능을 보이고 pre-trained 모델로 잘 동작한다. 그럼에도 많은 도전이 남은 부분이 detection, segmentation과 같은 task에 잘 적용되어야 한다는 것이다. 게다가 self-supervised learning도 large scale supervised 방식과의 gap이 존재한다.
사실 얼마전 다시 ViT에 필적할만한 논문을 구글에서 MLP-Mixer라는 논문으로 발표했다.
ViT와 거의 유사한 구조이나 MLP를 이용한 간단하지만 계산량이 적고 성능이 좋은 방법론이다. 다만 여전히 large-scale pretraining dataset이 필요하다는 점에서는 동일하므로 BiT -> ViT 를 잇는 연장선상에서 살펴보는 것도 의미 있을 것이다. 좀 더 효율적인 Transformer 기반 network는 DEIT를 살펴볼 필요가 있다.
'논문읽기' 카테고리의 다른 글
| RandAugment: Practical automated data augmentation with a reduced search space (google brain) (0) | 2020.05.29 |
|---|---|
| Deep Double Descent (0) | 2019.12.09 |
| Pose estimation 정리 링크 (0) | 2019.10.22 |
| GAN link 모음 (0) | 2019.09.28 |
| [CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation (0) | 2019.09.27 |

