
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Transformer #classification #SOTA #Google
- IvanLaptev
- ICCV19 #Real-World #FaceRecognition
- CVPR
- Realtime
- coco
- hourglass
- cornernet #simple #다음은centernet #hourglass생명력이란
- objectdetector
- centernet
- vit
- np-hard
- POSE ESTIMATION
- DeepDoubleDescent #OpenAI #어려워
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- Manmohan #UnconstrainedComputerVision
- XiaomingLiu #PersonIdentification
- Today
- Total
HyperML
(CenterNet) Objects as Points 본문
두 가지 종류의 CenterNet이 있다
하나는 본 논문 Objects as Points
나머지 하나는 CenterNet: Keypoint Triplets for Object Detection
둘다 arxiv.org 기준으로 19.04에 등재되었다.
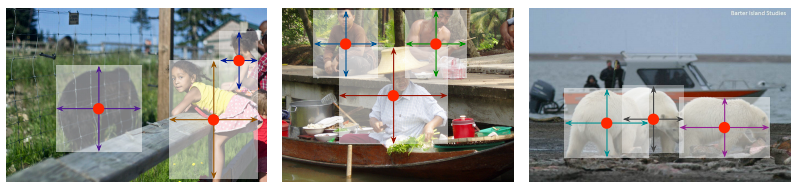
지난번 소개한 CornerNet 과 같이 keypoint heatmap 방식으로 object detection을 수행하는 논문들이 늘고 있는데 본 논문도 그런 흐름위에 있다.
Centernet의 특징은?
- 별도의 anchorbox없이 object detection을 object의 중앙에 놓인 point의 heatmap으로 결정한다는 점
- 중앙 point의 feature값으로 detection뿐 아니라 object size, dimension, 3D extent, orientation, pose등도 regression할 수 있다는 점
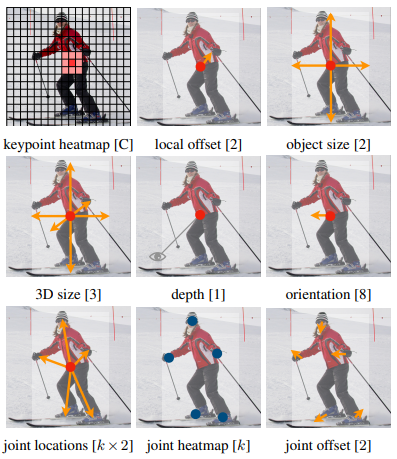
- nms가 필요 없다는 점
- 빠른 속도 (backbone에 따른 속도변화가 꽤 크다)
142fps@ResNet-18 (28.1% COCO AP),
52fps@DLA-34 (37.4% COCO AP),
1.4fps@Hourglass-104 (45.1% COCO AP)

- 다른 keypoint기반 object detector(CornerNet 2개, ExtremeNet 5개) 보다 적은수인 1개의 keypoint를 요구한다는 점
(다른 논문들은 동일 bounding box에 속한 keypoints확인을 위해 반드시 grouping 작업이 필요함)
(이는 keypoint 기반 알고리즘인 bottom-up 방식 2d pose estimation에서도 issue임(grouping에 많은 연산량 필요))
어떤 구조를 사용하였나?
- Stacked Hourglass Network, ResNet, DLA (Deep Layer Aggregation)를 실험에 사용했다.

- 이미 유사한 구조인 CornerNet때문인지 본문에는 별도의 network 구조에대해서는 그림이 없고 다만 위 구조들에 대한 성능만 간단하게 나와있다. 서플먼트에 아래와 같이 좀 더 구체적인 그림이 있다
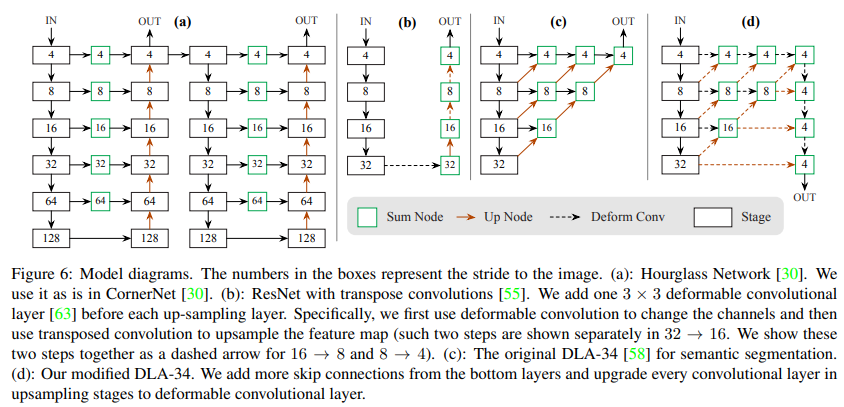
(a)는 Hourglass 구조인데, single person pose estimation에 사용된 backbone이다. hourglass특유의 반복적인 encoder-decoder 덕분에 반복을 거듭할 수록 refine되어 keypoint 위치가 정교해진다.
(b)는 resnet encoder-decoder
(c),(d)는 DLA-34 구조인데 (d)에서 약간 변형을 가해서 성능을 개선했다
loss
전체 loss는 다음과 같다
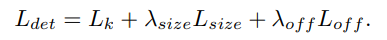
Lk는 gaussian kernel을 씌운 point의 위치를 focal loss로 계산한 것이고
Lsize는 예측한 bounding box (가로길이, 세로길이)와 실제의 box를 L1 loss를 계산한 것
Loff는 feature map을 축소했다가 원래 사이즈로 회복시키면서 발생하는 위치차(discretization error)를 보정하기 위한 loss이다
하나씩 보면,

Y : gaussian kernel을 씌운 ground truth center point 값
Yhat : gaussian kernel을 씌운 predicted center point 값

R은 stride (=4), p는 ground truth keypoint, p(tilde)는 low resolution equivalent
Ohat은 predicted local offset
기본은 L1 loss


Objects as points
예측한 object의 point(및 box size)를 가지고, bounding box 및 confidence(해당 점의 높이) 를 얻는다
몇가지 head를 달리함으로써 부가적인 기능을 수행할 수 있다
3D detction
keypoint estimator출력을 3차원 box를 predict할 수 있다.
point의 depth를 predict해서 다시 다음처럼 trasnformation 한다

이렇게 얻어진 것을 L1 loss로 학습한다
3d dimension(W,H,D)는 3개의 스칼라인데 이것은 별도의 head, L1 loss로 학습한다
orientation은 Mousavin을 따랐고, 그는 orientation을 2개의 bin으로 표현했다
각 bin에 4개씩 8개의 스칼라를 사용했다. 첫번째 bin에서 2개는 softmax classification, 나머지 2개는 각 bin의 angle을 regress했다.
각각의 loss는 아래와 같다


gamma는 object의 height, width, length이다 (meter)

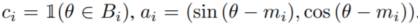
mi는 bin center, bi는 softmax classification, ai는 in-bin offset의 sin, cos 값이다
각 bin의 angle은 위 theta hat처럼 encoding 된다
j는 bin index인데 더 큰 classification score를 갖는 것이다

Human Pose Estimation
COCO keypoint 기준 17개(=k)의 관절부를 keypoint로 찾아주는 것이다.
(x,y 이므로 k * 2) 본 논문에서는 L1 loss로 바로 keypoint를 계산하고 가려진 keypoint는 제외하고 학습하였다
학습 결과를 refine 하기위해 일반적인 pose estimation 방식 두가지중 bottom-up 처리 방식을 사용했다(PAF, Stacked Hourglass, PersonLab)
좀 더 keypoint를 잘 예측하기 위해서 center offset을 grouping cue로 사용했는데, 각각의 keypoint를 center offset 기준으로 할당했다.
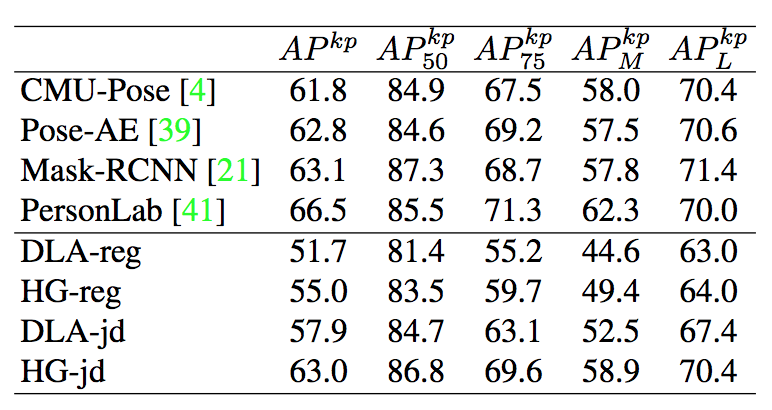
여러 구성에도 불구하고 SOTA수준은 아니지만, 준수하게 human pose에 대해서도 feature를 뽑아낸다는 것을 알 수 있다.
다만 Hourglass 구조 자체가 이미 single pose 전용으로 오래전에 발표된 것이기에 19년도에 발표된 본 논문이 해당 구조를 사용해서 pose estimation을 수행한 것은 아쉬움이 있다.
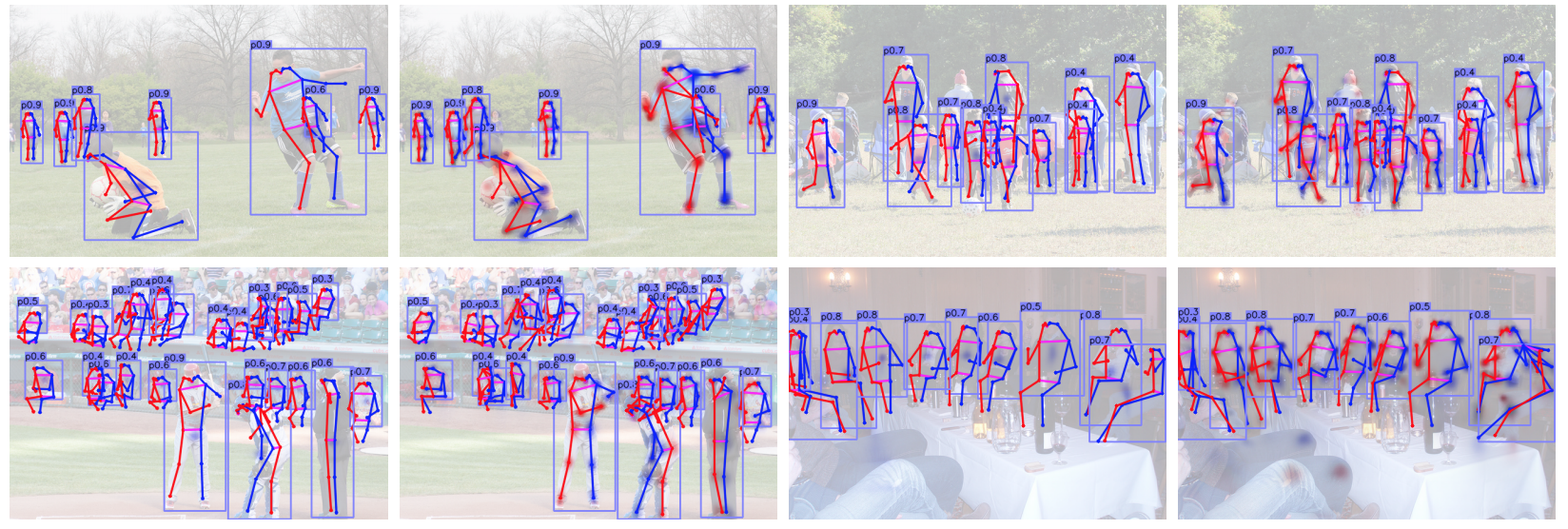
관련 링크
github : https://github.com/xingyizhou/CenterNet
'Object Detection' 카테고리의 다른 글
| [ECCV18]CornerNet: Detecting Object as Paired Keypoints (0) | 2019.12.10 |
|---|---|
| Object Detection (0) | 2019.12.07 |

