
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- ICCV19 #Real-World #FaceRecognition
- cornernet #simple #다음은centernet #hourglass생명력이란
- DeepDoubleDescent #OpenAI #어려워
- np-hard
- POSE ESTIMATION
- IvanLaptev
- Realtime
- XiaomingLiu #PersonIdentification
- Manmohan #UnconstrainedComputerVision
- CVPR
- coco
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- objectdetector
- vit
- Transformer #classification #SOTA #Google
- hourglass
- centernet
- Today
- Total
HyperML
[ECCV18]CornerNet: Detecting Object as Paired Keypoints 본문

CornerNet은 1-stage 계열에서 새로운 방식으로 등장한 object detector이다.
일반적으로 box를 나타내는 top-left, bottom-right 정보를 바로 keypoint detection으로 찾는 방식인데, 마치 2d human pose estimation에서 heatmap을 가지고 joint의 keypoint를 찾는 것과 유사하다.

기존의 1-stage detector와 무엇이 다른가?
1. bounding box를 pair corner point로 찾고 각각의 포인트의 embedding을 통해 pair를 구성한다. 100k에 이르는 anchor box가 필요하지 않다
2. corner pooling : left-most, top-most 검색을 하고, max인 교차점을 구한다
3. 1-stage detector중에서는 가장 우수한 편, 2-stage detector 와 비교해도 나쁘지 않은 수준 (아래 표)

어떤 구조를 사용하는가?

Hourglass 구조는 Newell et al. 저자들이 "Stacked Hourglass Networks for Human Pose Estimation" 논문에서 소개하였으며, 본 논문의 저자 중 한명인 Jia Deng이 해당 논문의 공저자이기도 하다.
마치 autoencoder와 유사하게 생긴 반복적인 모래시계(hourglass)형 네트워크를 통해 정제된 feature는 다시 top-left, bottom-right corner를 찾는데 사용된다.
다른 network도 backbone으로 사용해보았으나 hourglass가 가장 성능이 우수하여 선택했다고 한다.

위의 hourglass를 통과한 결과물인 heatmap이 class별, top-left별, bottom-right별로 생성된다.
각 heatmap의 point별로 다시 embedding이 계산되고, 이 embedding의 유사도를 측정하여 pair를 구성한다.

corner pooling은 위와 같은 방식으로 이루어지는데, feature map 우측에서 좌측으로 이동해오면서 발견한 max값을 발견위치부터 채워버린다. 아래에서 위 방향으로도 동일한 방식으로 하고, 두 개의 map을 elementwise add한다.
이것이 왜 필요하냐면, corner point가 보통 가장자리에 있어서 local evidence가 부족하여 무언가 존재하는 것으로부터 출발해야 하기 때문이다. 다만, pr12 youtube 논문읽기 모임에서 본 논문을 소개한 jaewon lee님이 우려하는 바처럼 CCTV영상에서 비슷한 위치에 여러 person이 존재할 경우 대응이 어려울 수 있을 듯 하다.

위는 corner point가 왜 local evidence가 부족한지를 분명하게 보여주는 예시이다.

변형된 residual net을 이용하였다. 첫번째 layer에 corner pooling을 집어넣고 출력단에 heatmap, embedding, offset을 나오게 했다. offset은 원 image를 downsampling 후 upsampling 하면서 정확히 pixel좌표를 보정하기 위해 필요하다고 한다.

heatmap으로 corner와 class를 찾고, embedding으로 pair를 짝짓는다. 매우 간단한 구조.
어떤 loss를 사용하는가?
object detector답게 여러가지의 loss를 사용한다. 먼저 모두 나열하자면 아래와 같다.




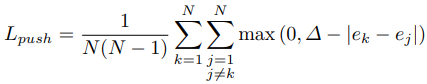
1, Ldet : focal loss의 변형이다. heatmap에 기여. p는 해당 위치에서의 score, y는 ground-truth이다. N은 image에서 object의 수, alpha(2), beta(4)는 각 point의 기여도를 조절하는 hyperparameter
2. SmoothL1Loss : offset에 기여. faster-rcnn에서 bounding box regression(RPN) 하는 loss인데, 여기서도 box의 위치를 regression한다. 이것저것 써봤으나 smoothl1loss가 가장 좋았다고 한다.
3. push/pull loss : embedding에 기여. Newell et al. 저자들의 "Associative embedding: End-to-end learning for joint detection and grouping"에서의 embedding 형식과 유사함. face recognition에서 contrastive 형태로 종종 사용되는 loss인데, 서로 같은 object끼리는 같은 embedding을 가지게 만들고 다른 object끼리는 gap을 두어 밀어내는 역할을 한다.
etk : top-left embedding, ebk: bottom-right embedding, ek: etk와 ebk의 평균
ej : ek와는 다른 클래스의 평균

우측 chart를 보면, embedding을 vector로 구성한 것이 아니라 scalar로 만들었다. 뭐든 작동되기만 하면야...
성능/속도는 어떠한가?

일단 1-stage에서는 최우수, mask r-cnn 보다는 조금 더 좋고, cascade r-cnn보단 조금 못한 수준.
속도는 244ms per image on a Titan X
1-stage이긴 한데 분명 1-stage들 중에서 우수한 AP인데, 속도는 2-stage detector 보다 못한 느낌이다.

참조 링크:
[pr12] https://www.youtube.com/watch?v=6OYmOtivQY8
[paper] https://arxiv.org/pdf/1808.01244.pdf
[ECCV18 oral] https://www.youtube.com/watch?v=aJnvTT1-spc
[author] https://heilaw.github.io/
'Object Detection' 카테고리의 다른 글
| (CenterNet) Objects as Points (0) | 2019.12.11 |
|---|---|
| Object Detection (0) | 2019.12.07 |

